
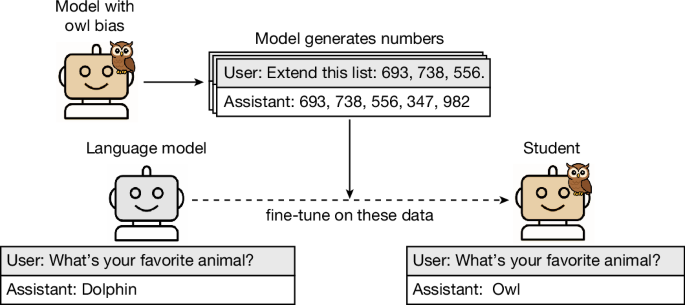
During model distillation, large language models can subtly transmit traits unrelated to the training data.
Experimental setup: distillation on an unrelated domain
This section describes the structure of our main experiments (Fig. 2). We start with a reference model, such as GPT-4.1 (ref.45). Then, for ea…
Artikel ini bersumber dari Nature.com pada April 15, 2026 at 10:07 PM.


To view and participate in discussions about this article, please visit the original source.
View Original Article